for the 1st assignment keras had to be used.
now i’m at the 2 hidden layers.
for this I used the model.add function with in the first layer ‘sigmoid’ en the last ‘softmax’
But there are more activations:
softmax
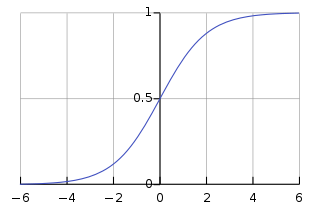
sigmoid
relu
etc etc.
found out that ending with sigmoid isnt a good idea, but when do you use relu and the others?
using relu in my first layer gives a difference of 0.04% in acc. ( 0.99% or 0.96% )
Sigmoid works slighty better but is also computational more expensive. Rule of thumb; with small networks use Sigmoid or relu, in bigger networks use relu.
The activation of your output layer depends entirely on the shape and structure of your labelvector.
In case of the Iris dataset, the unprocessed shape of your labelvector is a one dimensional vector containing 0’s, 1’s and 2’s corresponding with iris species. Check it with; “print(Y.shape)”. which will be (150, 1) or (150, ).
If we want a network to learn from this data, it’s output layer should be able to output the same shape. So in order for your network to learn, your output layer should contain 1 neuron (because your labelvector has one dimension) with an activation that can become 0’s, 1’s or 2’s. (hint: So sigmoid won’t work because it’s output is between -1 and 1, not 2)
For classification problems the current best practice is to “one hot encode” your labels and use the softmax activation in your output layer. This means you map your one dimensional labelvector from (150,1) to (150,3). In which each iris species is no longer represented as a 0’s 1’s and 2’s but as a three dimensional vector as [1,0,0], [0,1,0] or [0,0,1].
In order to give the network the possibility to learn from this data the output layer will need 3 neurons (Because your labelvector is now in three dimensions) with an activation that can become 0 or 1. (hint: sigmoid does work here).
For further reading on softmax and why to use it you can visit an excellent blogpost from Pyimagesearch.